


Musing #2: AI-powered Lofi Bollywood Music?
Will AI help or hurt the creative process?

Lofi Music Generation - Can AI really make music better? I decided to combine my passion for music and ML to explore this in 4 steps. You can check out the results below, peruse my video of the experiment flow and take a look at the google colab for code details and to try it yourself!
Loom Video Link (Attached Video Below)
My goal was to create a lofi bollywood sample so I started where you might expect...with the data.
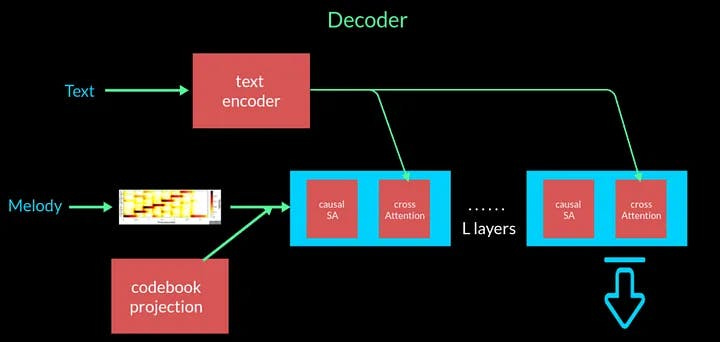
Data Gathering & Finetuning: I gathered ~150 lofi bollywood w/ ~2.5k clips of 30 seconds with simple descriptions to finetune the decoder of the MusicGen models for 5 epochs. The core idea behind MusicGen (vs. previous generators) is that it added text and melody conditioning.

The original model was trained on 20k hours across all genres, but I’m doubtful lofi bollywood played a role (see the Original Model link below). The original 300M param model did a great job creating indian instrumentals like the sitar and tabla but did not create a lofi vibe. In order to help this model along, I decided finetuning could help and so collected my own dataset w/ 20.8 hours (1/1000x of the original), and finetuned the 300M param model (due to limited GPU compute) however I did see a noticeable improvement when prompting the original and finetuned 300M param (limited GPU compute) MusicGen model with “indian lofi beat with eastern instrumentals” in terms outputting a lofi vibe.
Original Model (AI) : https://voca.ro/1dRCve3mCCg1
Finetuned Model (AI) : https://voca.ro/1fbsdfT1dObF
Manual Intervention: To create a somewhat fair comparison, I aimed to use the AI as a human and focus on music continuation, by giving it a bit of music and see how it extends it. But first…I made a few modifications in Ableton - especially around the speed, crackle and adding indian instruments like a sitar and percussion.
My Edited Clip (AI + Human): https://voca.ro/1fRBVK6utNT3
Music Continuation: Prompted the finetuned model with 10 second clip of my edition to see what the last 10 seconds might sound like. Needless to say…it left much to be desired.
Audio-only Continuation (AI): https://voca.ro/1eciGnvUcyle
Music Continuation (w/ text): Prompted the finetuned model with a 5 second clip of my edition and a text prompt “chill relaxed indian lofi with soft vocals and a tabla”. After the first 5 seconds it adds an interesting twist to the song.
Audio + Text Continuation (AI): https://voca.ro/170HqVp3eHDW
The human ear is the best discriminator for consonance vs. dissonance and well…the music continuation wasn’t great without text prompting and even then it was interesting but quality could still be improved.
MusicGen was helpful in seeding an initial musical idea and extending an idea and transitioning to a new beat and ending a song (albeit not my initial intention). However, the work needed to obtain this was not worth the effort for most musicians, so a few things could be improved
Reducing friction is key to making this a viable sample generator during the creative process
For longer form generation, stringing outputs together is likely the most computationally viable way to make generative AI a useful tool
Audio quality is still not great from many of these outputs, but for production level audio a sound engineering pipeline will need to accompany these outputs
This was a very simple experiment, but musicians rarely use language to describe music in the development process — instead we “jam” with other musicians going back-and-forth with samples. Given all of this I have some ideas for where to go from here.
Next Steps
Share code and notebooks from this experiment to see what others get
Test other transformer-based music encoder-decoder architectures (e.g. MusicLM) and diffusion models (Riffusion)
Extend the lofi dataset and acquire more GPU resources to train deeper models.
String together models to create an organic “jam” session and longer samples (especially using language as an intermediate representation)
I have no idea where this is going, but I’m excited to see where it takes me and if nothing else, I’ll hopefully create my own “jam buddy” to expand my creative process.
References and Credits:
MusicGen HF: https://huggingface.co/spaces/facebook/MusicGen
MusicGen Github: https://github.com/facebookresearch/audiocraft
MusicGen Trainer (c/o neverix): https://github.com/neverix/musicgen_trainer/tree/main
Stay tuned for more…
✌🏽