
Musing #3: 🎹 MIDI Representations & AI 🤖- A History & Tutorial
introducing the format that powers music production, AI MIDI generation models over the years, and how to format MIDI files to work with them

MIDI as a protocol was developed in 1983 to standardize musical notes and pitches across musical instruments. It enabled drums, pianos, synths and everything in between to be represented in a standard discretized format, which made digital instruments possible. Of course since then there has been lots of work trying to convert MIDI instruments to sound like real sounds to simplify recording. MIDI enabled a number of use cases at that time:
musicians can create melodies and drums without having to record in a studio (quiet atmosphere and perfect sound isolation) since you can posthoc process sounds to match the pitch.
different instruments can interact - you can create a melody in one instrument (even a computer keyboard) and modify it on another
simplified and democratized music production by enabling a common language, expanding the range of possible sounds for music producers and expanding the reach of music production capabilities.

This post is pretty long…but the hope is that after this you will have learned the following:
What is a MIDI file and how to manipulate it in python at a basic level?
What are some of seminal MIDI Generation papers and what MIDI representations do they use for training / inference?
How to convert MIDI files to these various formats for use in these models?
If you’re only interested in some of the above, jump to the section below and click on the Google Colab link to take you directly to that section in the notebook. All of our notebooks and code for this blog are also on Github
Enjoy!
MIDI Basics
Turns out that MIDI’s discrete nature also makes it much easier to represent as a matrix and to leverage in machine learning models to predict the next sequence. MIDI is used in every Digital Audio Workstation (DAW) as Ableton, Garageband, Logic Pro, etc. for music production, and so musicians are also very familiar with working with these tools. Let’s first take a look at what a MIDI file is…

MIDI files consist of a bunch of messages in sequential order, and can represent 128 different pitches at various intervals, durations and velocities. The files themselves are in byte-encodings so reading them in a text editor doesn’t yield much, but python libraries like mido provide a simple way to parse these messages. Since it’s not required for our exploration, the interested reader can read about byte-encodings here.
Quick Side Note: throughout this post I use 3 key python libraries for working with MIDI files each with their own pros/cons. You can find more details here:
mido(link), pretty_midi(link), pypianoroll(link)
Example Track (“Roja” by A.R. Rahman)
We use a simple melody from the TheoryTab dataset, which has both melody and chords for thousands of songs. We downloaded the melody for “Roja” which looks something like this:

You can also visualize these in standard musical notation using a tool like MuseScore

In true MIDI form, we assign any instrument we want to this to create a sound from the MIDI file. Here are a few examples:
Piano
Mandolin
String-Ensemble Synth (Audio Recording - has some ambient noise)
Exploring MIDI File Structure
A MIDI file is a combo of messages which look something like below. We use mido to parse and print out the messages via python. More details in the Colab, but here’s a quick preview. Put simply, there are meta messages and musical messages, where meta messages set things like time signature, key signature, tempo, etc. while musical messages specify specific the pitch, velocity and duration of notes to be played. MIDI files keep time using “ticks” which, based on tempo, time signature and BPM can be converted into seconds.
MidiFile(type=1, ticks_per_beat=480, tracks=[
MidiTrack([
MetaMessage('set_tempo', tempo=631579, time=0),
MetaMessage('time_signature', numerator=4, denominator=4, clocks_per_click=24, notated_32nd_notes_per_beat=8, time=0),
MetaMessage('key_signature', key='E', time=0),
MetaMessage('marker', text='4_4_m_5_', time=0),
MetaMessage('marker', text='11_11__5_', time=960),
...
MetaMessage('marker', text='4_4__5_', time=960),
MetaMessage('marker', text='9_9__5_', time=960),
MetaMessage('marker', text='11_11__5_', time=960),
MetaMessage('end_of_track', time=1)]),
]),
MidiTrack([
MetaMessage('track_name', name='melody', time=0),
Message('program_change', channel=0, program=0, time=0),
Message('note_on', channel=0, note=64, velocity=80, time=0),
Message('note_on', channel=0, note=64, velocity=0, time=480),
Message('note_on', channel=0, note=67, velocity=80, time=0),
...
Message('note_on', channel=0, note=67, velocity=0, time=0),
Message('note_on', channel=0, note=66, velocity=0, time=480),
MetaMessage('end_of_track', time=1)])
])In this section of the Colab we go message-by-message and interpret them to gain an appreciation for the way these files work (and perhaps a motivation for why certain representations are used in MIDI generation models).
MIDI Generation Models - Through the Years
If we look at some of the core papers looking at MIDI generation there have been a number in the past few years - I won't try to be completely comprehensive here but I will note some of the important ones. The most notable ones in ~chronological order are (and coincidently, though unsurprisingly, grouped by models which correspond to the most popular types of models at the time):
RNN-Based
MelodyRNN (Jul 2016) [Paper, Code, Website]: LSTM based model for MIDI inputs
Derivatives: DrumsRNN, ImprovRNN, PerformanceRNN, MusicRNN
DeepBach (Dec 2016) [Paper, Code, Website]: a Steerable Model for Bach Chorales Generation
GAN-Based
MidiNet (Mar 2017) [Paper, Code, Website]: Convolutional GAN-based sequential prediction of MIDI nodes with conditioning options for chord sequences and melody of previous bars
MuseGAN (~2017) [Papers, Code, Website]: GAN-based model for generating multi-track MIDI files
VAE-Based
MusicVAE (Mar 2018) [Paper, Code, Website]: Interpolate between two 16 bar midi notes for smoothness, realism and expression
Derivatives: GrooVAE
Transformer-Based
Music Transformer (Dec 2018) [Paper, Code, Website]: Transformer-based model for generating multi-track MIDI files
MuseNet (~2019) [Paper, Code, Website]: GPT-2 based model for generating multi-track MIDI files
Most importantly, they all use some form of a sequence as an input for training and inference. What we'll focus on first, is the question: what format do these models expect the input to be in?
NOTE: We are explicitly ignoring the question of preprocessing datasets (i.e. what format do datasets come in and how to transform them), which we will defer to the next post since it is important for training these sequence models above or creating our own to craft a training set which may include multiple sources that need to be standardized to a single input format. For now, we assume we have a MIDI file present as above and convert them to a format usable for training. We will also defer augmentation and other adjustments (e.g. transposition, tempo adjustments, etc.) to the next post where we'll discuss considerations for training the models.
Binary Piano Roll Representations
The piano roll representation is a common way to represent music data. It consists of a two-dimensional matrix where the rows represent time steps and the columns represent pitches (and special symbols in certain variations). The entries of the matrix are often non-negative.
One example is when the entries are binary, indicating whether a note is played at a given time step and pitch.
X ∈ {0, 1}^(h×w) where h is the number of pitches and w is the number of time steps.
NOTE: velocity and complex time signature differences are IGNORED in this version!

Another variation on this form also considers the velocity of the note. In this case, the entries are integers in the range of 0-127 indicating the velocity of the note played at a given time step and pitch. In this first section, we will talk about the models that look at only the binary piano roll representation, but will revisit the velocity in the next section.
X ∈ [0,127]^(h×w)
NOTE: The number of pitches in a MIDI file is 128, however the dimension of h may be reduced to narrow the range of notes to a specific instrument (e.g. 88 keys in a piano) or can be expanded to include silence or rests (e.g. 129/130 or 89/90). The time steps also depend on the model and level of granularity desired. For coherence, many models filter inputs to 4/4 time signatures and use sixteenth notes as a single time step (16 steps / bar).
For the RNN-Based, GAN-Based and VAE-Based models above, at some level all of these look at splitting the MIDI files into discrete time bars and ignoring the velocity. However they vary in how they split the bars and the granularity of notes they use.
RNN-Based
MelodyRNN: "[60, -2, 60, -2, 67, -2, 67, -2]” (-2 = no event, -1=note-off event, 0-127 = note-on event for that MIDI pitch) for each track. 4/4 time signature with 16th notes as a single time step. Each bar has 16 time steps. Samples can be 2 bars or 16 bars.
DeepBach: 4 tracks/rows (soprano, alto, tenor, bass) with 16 time steps per bar (16th notes) represented by strings for the 128 pitches
C1toG9and a hold__(i.e. 129 total pitches), two additional rows are added with0or1to indicate fermata and the beat count (e.g.1,2,3,4)
GAN-Based
MidiNet: piano roll representation in 4/4 time signature with 16th notes as a single time step. Each track is a new channel (e.g. CxHxW). Each sample is 1 bar and each value can be one of 128 MIDI pitches or silence resulting in a Cx129x16 matrix for each bar.
MuseGAN: piano roll representation in 4/4 time signature with 16th notes as 6 time steps. That is each bar has 96 time steps. Each track is a new channel and each sample is 1 bar (e.g. CxHxW). Each value can be one of 128 MIDI pitches resulting in Cx128x96 matrix for each bar. The dimensions are rearranged to be 96x128xC.
VAE-Based
MusicVAE: "[60, -2, 60, -2, 67, -2, 67, -2]” (-2 = no event, -1=note-off event, 0-127 = note-on event for that MIDI pitch) for each track. 4/4 time signature with 16th notes as a single time step. Each bar has 16 time steps. Samples can be 2 bars or 16 bars.
Observations:
All of these models use 4/4 time signature and a 16th note or some subset of them as a time step. This is likely because it helps with standardization and structure of the data. For examples if we processed 6/8 or 5/4 time signatures and split them with the same time steps as 4/4, we would capture motifs that span bars which may not be consistent. And since the majority of pieces are 4/4, it is advantageous to use that time signature and discard others.
All representations discard the velocity of the notes. This is likely because it is not as important for the melody and the models then not as sensitive to it, that is, there is less to learn. Velocity variations could also be added posthoc to make the outputs seem more realistic.
Representations of the matrix are still highly variable and depends on the model, the DL library (TF, Pytorch, etc) and the application. We'll next explore code to transform MIDI files to these formats. For the above models we'll focus on the following 3 common formats which were most common:
Compressed Piano Roll Representation w/ Pitch Indices (CxW): MelodyRNN, MusicVAE
Compressed Piano Roll Representation w/ Note Names (CxW): DeepBach
One/Multi-Hot Piano Roll Representations (CxHxW): MidiNet, MuseGAN
1. Compressed Piano Roll Representation w/ Pitch Indices (CxW)
These representations are used commonly by the Google Magenta team across MelodyRNN and MusicVAE and represent each time step with an absolute pitch index 0-127 rather than a 1-hot or multi-hot encoding. Since it is can only represent 1 note per time step, the channels or C dimension enable multiple instruments or notes to be represented. We ignored the -1 note-off event and defaulted to -2 for no event for time steps where the note is not playing.
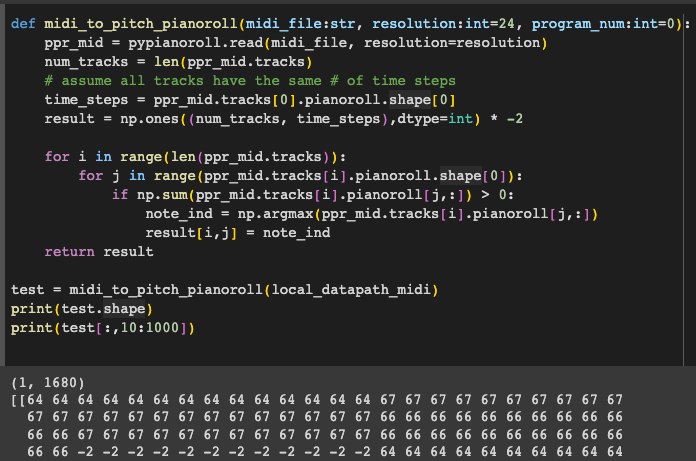
2. Compressed Piano Roll Representation w/ Note Names (CxW)
Here we use a very similar approach to above, but convert the notes and like it is described in DeepBach, we use the __ symbol for a hold where there are no notes playing.

3. One/Multi-Hot Piano Roll Representations (CxHxW)
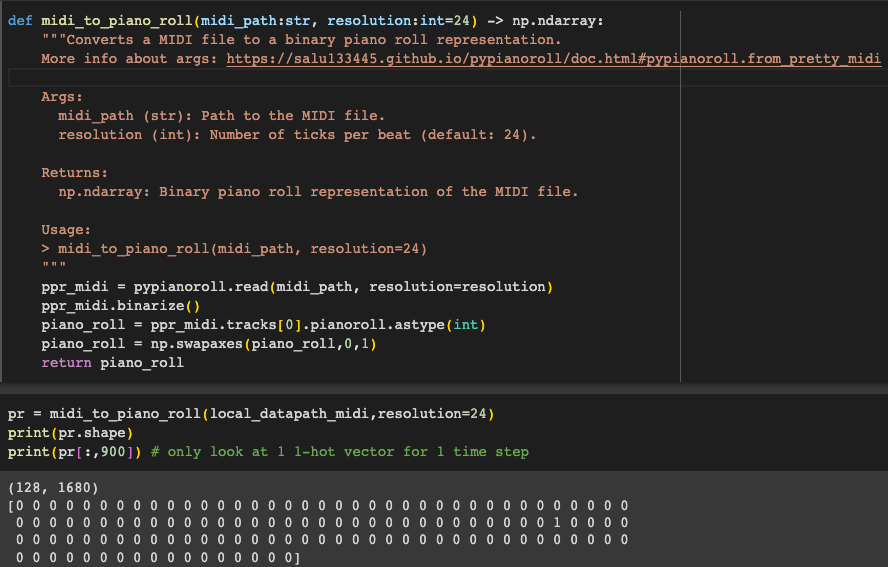
The one/multi-hot piano roll representation is the classic representation used by MidiNet and MuseGAN and ignore the velocity which means that the piano roll representation they adhere too is the binary one: X ∈ {0, 1}^(H×W) as shown above in the binary piano roll format.
Here the output of the piano roll will be a matrix with 128 rows (H) to signify the 128 different pitch levels (note a piano only has 88). The columns (W) will be the time steps. The values will be 1 or 0 to signify whether the note is played or not as a one-hot encoding.
We can define a simple function to convert a MIDI file to this simple format. We'll use the pretty_midi library to parse the MIDI file and then use the pypianoroll library to convert it to a piano roll representation.
Expressive Piano Roll & Language-Based Representations
Following in the footsteps of recent language models, transformer based models can use more expressive piano roll and language-based encodings to represent the MIDI files. In particular, language modeling has often used byte-pair encodings (BPE) to represent words as a sequence of bytes. This is a great way to represent words because it allows for a variable length encoding of words and allows for the model to learn sub-word representations.
Let's explore what the Transformer based models use to represent MIDI files.
Transformer-Based
Music Transformer (Google): Multiple formats for different datasets and experiments
JS Chorales Bach: (similar to DeepBach) uses the following sequence of 4 voices (soprano, alto, tenor, bass) in 4/4 time in sixteenth note increments

Inputs are serialized $S_1A_1T_1B_1S_2A_2T_2B_2$ and each token is represented as a one-hot vector → 128 x (WxC) where W is number of sixteenth notes and C is the number of channels - in this case 4 for each voice
Piano E Competition Dataset: [Ref: https://arxiv.org/pdf/1808.03715.pdf] → Use a set of sequence events like the following.

Overall the total number of sequences are eventually represented as a sequence of 1-hot vectors representing each of the 388 possible events -> 388 x T where T is the the number of 10ms increments in the sample. This representation for the Piano competition dataset is discussed in section 6.1 of this paper.
128
NOTE-ONevents: one for each of the 128 MIDI pitches. Each one starts a new note.128
NOTE-OFFevents: one for each of the 128 MIDI pitches. Each one releases a note.100
TIME-SHIFTevents: each one moves the time step forward by increments of 10 ms up to 1 s.32
VELOCITYevents: each one changes the velocity applied to all subsequent notes (until the next velocity event).
MuseNet (OpenAI):
bach piano_strings start tempo90 piano:v72:G1 piano:v72:G2 piano:v72:B4 piano:v72:D4 violin:v80:G4 piano:v72:G4 piano:v72:B5 piano:v72:D5 wait:12 piano:v0:B5 wait:5 piano:v72:D5 wait:12 piano:v0:D5 wait:4 piano:v0:G1 piano:v0:G2 piano:v0:B4 piano:v0:D4 violin:v0:G4 piano:v0:G4 wait:1 piano:v72:G5 wait:12 piano:v0:G5 wait:5 piano:v72:D5 wait:12 piano:v0:D5 wait:5 piano:v72:B5 wait:12


Observations:
Transformer-based model representations are more flexible and leverage expressivity (velocity) and polyphonicity.
Transformer-based model representations only require sequential processing but are open to using one-hot vectors (i.e. pianoroll representations) as well as language based ones (i.e. MuseNet).
Representations can be broken down in the following ways:
One-hot Binary Piano Roll Representations (128x(WxC)): Music Transformer (JS Chorales Bach)
One-hot Expressive Piano Roll Representations (388xW): Music Transformer (Piano E Competition)
Sequential Encoding & Tokenization (???): MuseNet
1. One-hot Binary Piano Roll Representations (128x(WxC))
This is not too dissimilar from our previous work on representations except that it allows for combining the channels from different instruments into 1 dimension which means that W (the time dimension) and C (the channel dimension) are combined. It also means that an encoder and decoder must be present to identify these differences. Given we only have 1 track, the output will not be any different for our trial MIDI file, however we define a function that would work for multiple tracks. Our second dimension is WxC (in our case 1680x1=1680)

2. One-hot Expressive Representation (388xW) - 1 Track
This is a unique approach because it takes into account timing and velocity. It is also a one-hot representation, but it is not a piano roll representation. Instead it is a sequence of events that are encoded as one-hot vectors. To recap, the events we care about are:
128
NOTE-ONevents: one for each of the 128 MIDI pitches. Each one starts a new note.128
NOTE-OFFevents: one for each of the 128 MIDI pitches. Each one releases a note.NOTE-ONwith velocity 0 is equivalent toNOTE-OFF.100
TIME-SHIFTevents: each one moves the time step forward by increments of 10 ms up to 1 s.32
VELOCITYevents: each one changes the velocity applied to all subsequent notes (until the next velocity event).
Our MIDI file is fairly standard in that it has just 1 velocity across all monophonic notes. Therefore, we will see very standard representations for this. However, if we had a more expressive MIDI file with multiple instruments and velocities, we would see more VELOCITY events. You might have noticed that we could add more events here to the vocabulary to expand the 1-hot representation to include other musical events like TEMPO or KEY_SIGNATURE or TIME_SIGNATURE or PROGRAM_CHANGE or CONTROL_CHANGE (e.g. pedal, levers,etc.) or PITCH_WHEEL, etc. However, we'll leave that for a future post. These are the events used in Musical Transformer.

3. Sequential Encoding & Tokenization (???)
While MuseNet was one of the most interesting applications of MIDI-based music generation using GPT-2 and Sparse Transformers, the blog post was "sparse" in its explanation of the encoding. Since the tokens were not explained I am not entirely sure how to convert the language sequence provided to discrete tokens to train a model (e.g. byte-pair encoding). We'll use some combination of expressive representations in 2 and 3 to train our own transformer-based model in a future post.
For now, we'll write some code to convert a MIDI file to a format similar to the one mentioned in their blog post - all timings in ticks and all notes in MIDI pitch values.:
bach piano_strings start tempo90 piano:v72:G1 piano:v72:G2 piano:v72:B4 piano:v72:D4 violin:v80:G4 piano:v72:G4 piano:v72:B5 piano:v72:D5 wait:12 piano:v0:B5 wait:5 piano:v72:D5 wait:12 piano:v0:D5 wait:4 piano:v0:G1 piano:v0:G2 piano:v0:B4 piano:v0:D4 violin:v0:G4 piano:v0:G4 wait:1 piano:v72:G5 wait:12 piano:v0:G5 wait:5 piano:v72:D5 wait:12 piano:v0:D5 wait:5 piano:v72:B5 wait:12

Conclusions
MIDI data is definitely here to stay! In the last 40 years it has gone from creating robotic like synthetic sounds, so the basis of all modern compositions (i.e. it would be hard to find any music producer today who doesn’t use MIDI for at least some tracks and layers). If you’ve made it this far, 👏🏽 CONGRATS! 🎉 By now, you should be able to answer these questions.
What is a MIDI file and how to manipulate it in python at a basic level?
What are some of seminal MIDI Generation papers and what MIDI representations do they use for training / inference?
How to convert MIDI files to these various formats for use in these models?
In addition, I had a few observations from this post which will hopefully be useful in our following posts.
MIDI Outputs Sound Real: MIDI outputs can easily sound crisp when interpreted by Digital Audio Workstations (e.g. Ableton Live, Garageband, etc) because digital instruments have gotten very sophisticated, emulating timbre, bass and even the mechanical sounds of instruments.
Transformer Models Represent Long Term Structure Best: MIDI models have been around for a long time, though in the last 5 years they have blown up with progress in sequential models from RNNs, GANs, VAEs and Transformers. The naturally sequential nature of MIDI files has been a perfect match which is shown in the impressive improvement in performance over time, with transformer-based models leading the pack in expressiveness because the sequences leverage velocity, polyphonicity and the dynamics of MIDI instruments. Transformer models have also shown to represent long term structure (unsurprising given similar results in language) on subjective human evaluations, making transformers the leading candidate for future models.
MIDI Model Tensor Data Formats are Disparate: MIDI-based Music Generation data models use very different formats where each is nearly bespoke for each model. While many great python tools like
pypianoroll,pretty_midi, andmidoexist, there isn’t an easy way to convert back-and-forth between standard MIDI formats and the different formats used for models. We believe this is because the datasets used (i.e. monophonic like our melody, polyphonic classical, polyphonic rock, multi-track, etc) also play a large part in the ways the model developers consider how to represent inputs and how they discretized the time steps.
Next Steps
In this post, we assume we have 1 MIDI file, but real training datasets can have a diversity of information and parsing and cleaning them, requires further consideration. Given our conclusions, here are a few next steps:
Explore building MIDI generation training datasets by parsing and cleaning open source MIDI data as well as creating our own. In the process, develop a simple library to transform between data formats and tensor formats.
Train our own models to create our own compositions by taking a deeper dive into MIDI generation models, esp. transformer models since they are flexible and we can experiment with the latest architectures being used for language modeling. We can also choose to use the same encodings as the models above or we can experiment with other encodings that express similar or even additional information and see how models respond to those additional parameters.
Until next time
✌🏽 Anand
A very exciting article on the MIDI format and creating music through Generative AI! Looking forward to the next post!